| 5. FEJEZET | Tartalom | 7. FEJEZET |
6. FEJEZET:
Struktúrák
A struktúra egy vagy több, esetleg különböző típusú változó együttese, amelyet a kényelmes kezelhetőség céljából önálló névvel látunk el. Néhány nyelvben az így értelmezett struktúrát rekordnak nevezik (pl. a Pascal rekordja hasonló tulajdonságú adatfajta). A struktúra bevezetése segíti az összetett adathalmazok szervezését, ami különösen nagy programok esetén előnyös, mivel lehetővé teszi, hogy az egymással kapcsolatban lévő változók egy csoportját egyetlen egységként kezeljük, szemben az egyedi adatkezeléssel.
A struktúrára az egyik hagyományos példa a bérszámfejtési lista: ez az alkalmazottakat attribútumok halmazával (név, lakcím, társadalombiztosítási szám, bér stb.) írja le. Ezen attribútumok némelyike maga is lehet struktúra, pl. a név is több részből áll, csakúgy mint a cím vagy a bér. A másik, C nyelvre jellemzőbb példát a számítógépes grafika adja: a pont egy koordinátapárral írható le, a négyzet egy pontpárral adható meg stb.
A struktúrákat érintő, az ANSI szabványból adódó legfontosabb változás, hogy a szabvány értelmezi a struktúrák értékadását. A struktúrák átmásolhatók egymásba, értékül adhatók más struktúráknak, átadhatók függvénynek és a függvények visszatérési értékei is lehetnek. Ezt évek óta a legtöbb fordítóprogram támogatja, de ezeket a tulajdonságokat most pontosan definiáljuk. A szabvány lehetővé teszi az automatikus tárolási osztályú struktúrák és tömbök inicializálását, amivel szintén ebben a fejezetben foglalkozunk.
6.1. Alapfogalmak
Hozzunk létre néhány struktúrát, amelyek a grafikus ábrázoláshoz használhatók. Az alapobjektum a pont, amely egy x és egy y koordinátával adható meg. Tételezzük fel, hogy a koordináták egész számok. A két komponens (koordináta) egy struktúrában helyezhető el astruct pont { int x; int y; };deklarációval.
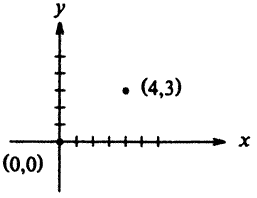
A struktúra deklarációját a struct kulcsszó vezeti be, amelyet kapcsos zárójelek között a deklarációk listája követ. A struct kulcsszót opcionálisan egy név, az ún. struktúracímke követheti (mint a példánkban a pont). Ez a címke vagy név azonosítja a struktúrát és a későbbiekben egy rövidítésként használható a kapcsos zárójelek közötti deklarációs lista helyett.
A struktúrában felsorolt változóneveket a struktúra tagjainak nevezzük. Egy struktúra címkéje (neve), ill. egy tagjának a neve és egy közönséges (tehát nem struktúratag) változó neve lehet azonos, mivel a programkörnyezet alapján egyértelműen megkülönböztethetők. Továbbá ugyanaz a tagnév előfordulhat különböző struktúrákban, bár célszerű azonos neveket csak egymással szoros kapcsolatban lévő adatokhoz használni.
Egy struct deklaráció egy típust is definiál. A jobb oldali, záró kapcsos zárójel után következhet a változók listája, hasonlóan az alapadattípusok megadásához. Így pl. a
struct {...} x, y, z;
szintaktikailag analóg az
int x, y, z;
deklarációval, mivel mindkét szerkezet a megadott típusú változóként deklarálja x, y és z változót és helyet foglal számukra a tárolóban.
Az olyan struktúradeklaráció, amelyet nem követ a változók listája, nem foglal helyet a tárolóban, csak a struktúra alakját írja le. Ha a struktúra címkézett volt, akkor a címke a későbbi definíciókban a struktúra konkrét előfordulása helyett használható. Például felhasználva a pont korábbi deklarációját a
struct pont pt;
definíció egy pt változót definiál, ami a struct pont-nak megfelelő típusú struktúra. Egy struktúra úgy inicializálható, hogy a definíciót az egyes tagok kezdeti értékének listája követi. A kezdeti értékeknek állandó kifejezéseknek kell lenni. Például:
struct pont maxpt = { 320, 200 };
Egy automatikus struktúra értékadással vagy egy megfelelő típusú struktúrát visszaadó függvény hívásával is inicializálható.
Egy kifejezésben az adott struktúra egy tagjára úgy hivatkozhatunk, hogy
struktúra-név.tagA pont struktúratag operátor összekapcsolja a struktúra és a tag nevét. A pt pont koordinátáit pl. úgy írathatjuk ki, hogy
printf("%d, %d", pt.x, pt.y);
A pt pont origótól mért távolsága:double dist, sqrt(double); dist = sqrt((double)pt.x * pt.x + (double)pt.y * pt.y);A struktúrák egymásba ágyazhatók. Például egy téglalap az átlója két végén lévő pontpárral írható le,
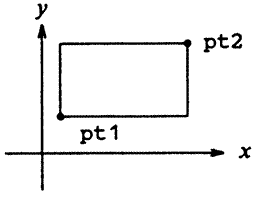
struct tegla { struct pont pt1; struct pont pt2; };Ennek alapján a tegla struktúra két pont struktúrából áll. Ha az abra struktúrát úgy deklaráljuk, hogy
struct tegla abra;
akkor azabra.pt1.xhivatkozás az abra pt1 tagjának x koordinátáját jelenti.
6.2. Struktúrák és függvények
A struktúrák esetén megengedett művelet a struktúra másolása vagy értékadása, ill. a struktúra címéhez való hozzáférés az & operátorral és a struktúra tagjaihoz való hozzáférés. Ezek a műveletek a struktúrát egy egységként kezelik, és a másolás vagy értékadás magában foglalja a struktúrák függvényargumentumkénti átadását, ill. a struktúra típusú függvényvisszatérés lehetőségét is. Struktúrák egy egységként nem hasonlíthatók össze. A struktúrák állandó értékek listájával inicializálhatók, és automatikus tárolási osztályú struktúrák kezdeti értéke értékadással is beállítható.
A struktúrák tulajdonságainak vizsgálatához írjunk néhány függvényt, amelyek pontokkal és téglalapokkal manipulálnak. A feladat megoldásának három lehetséges módja van: a függvénynek átadjuk az egyes komponenseket, a teljes struktúrát vagy annak mutatóját. Mindegyik módszernek van előnye és hátránya.
Az első függvény legyen a makepoint, amelyet két egész értékkel hívunk és visszatér egy pont struktúrával.
/* makepoint: egy pont struktúrát csinál az x és y komponensekből */ struct pont makepoint (int x, int y) { struct pont temp; temp.x = x; temp.y = y; return temp; }Vegyük észre, hogy nincs konfliktus abból, hogy az argumentum és a struktúratag neve megegyezik: az összefüggés kiértékelésekor újra felhasználja a rendszer a nevet. A makepoint függvényt bármilyen struktúra dinamikus inicializálására vagy struktúrák függvényargumentumként történő átadására használhatjuk. Például:
struct tegla abra; struct pont kozep; struct pont makepoint(int, int); abra.pt1 = makepoint(0, 0); abra.pt2 = makepoint(XMAX, YMAX); kozep = makepoint((abra.pt1.x + abra.pt2.x)/2, (abra.pt1.y + abra.pt2.y)/2);A következő lépésben pontokkal aritmetikai műveleteket végző függvényeket hozunk létre. Például:
/* addpoint: két pont összeadása */ struct pont addpoint(struct pont p1, struct pont p2) { p1.x += p2.x; p1.y += p2.y; return p1; }Ennek a függvénynek a két argumentuma és a visszatérési értéke egyaránt struktúra. A függvényben átmeneti változó bevezetése nélkül, közvetlenül a p1 komponenst növeltük, hogy kihangsúlyozzuk, a struktúra típusú paraméterek éppen úgy érték szerint adódnak át, mint bármely más változó.
A következő példa a ptinrect függvény, amely azt ellenőrzi, hogy egy adott pont benne van-e egy téglalapban. Megállapodás szerint a téglalap belsejének tekintjük annak alsó és bal oldali határát, viszont a teteje és a jobb oldali határa már nem része a téglalapnak.
/* ptinrect: visszatérés =1, ha p benne van a téglalapban és =0, ha nincs */ int ptinrect(struct pont p, struct tegla r) { return p.x >= r.pt1.x && p.x < r.pt2.x && p.y >= r.pt1.y && p.y < r.pt2.y; }A függvény feltételezi, hogy a téglalapot a szokásos formában írtuk le, azaz a pt1 koordináta kisebb, mint a pt2. A következő függvény visszatérési értékül egy ilyen kanonikus alakú téglalapot mint struktúrát ad.
#define min(a, b) ((a) < (b) ? (a) : (b)) #define max(a, b) ((a) > (b) ? (a) : (b)) /* canonrect: kanonizálja a téglalap koordinátáit */ struct tegla canonrect(struct tegla r) { struct tegla temp; temp.pt1.x = min (r.pt1.x, r.pt2.x); temp.pt1.y = min (r.pt1.y, r.pt2.y); temp.pt2.x = max (r.pt1.x, r.pt2.x); temp.pt2.y = max (r.pt1.y, r.pt2.y); return temp; }Ha nagy struktúrát kell átadnunk egy függvénynek, akkor sokkal hatékonyabb, ha a struktúra mutatóját adjuk át és nem pedig a teljes struktúrát másoljuk át. Egy struktúrához tartozó mutató éppen olyan, mint egy közönséges változó mutatója. A struktúra mutatójának deklarációja:
struct pont *pp;
Ez egy struct pont típusú struktúrát kijelölő mutatót hoz létre. Ha pp egy pont struktúrát címez, akkor *pp maga a struktúra, és (*pp).x, ill. (*pp).y pedig a struktúra tagjai. A pp értékét felhasználva pl. azt írhatjuk, hogystruct pont kezdet, *pp; pp = &kezdet; printf("kezdet: (%d, %d)\n", (*pp).x, (*pp).y);A zárójelre a (*pp).x kifejezésben szükség van, mert a . struktúratag operátor precedenciája nagyobb, mint a * operátoré. A *pp.x kifejezés azt jelentené, mint a *(pp.x), ami viszont szintaktikailag hibás, mivel jelen esetben x nem mutató.
A struktúrák mutatóit gyakran használjuk egy új, rövidített jelölési formában. Ha p egy struktúra mutatója, akkor a
p-> struktúratag
kifejezés közvetlenül a struktúra megadott tagját címzi. A -> operátor a mínusz jel és a nagyobb jel egymás után írásával állítható elő. Ezt felhasználva az előző példa printf függvényét úgy is írhatjuk, hogyprintf("kezdet: (%d, %d)\n", pp->x, pp->y);A . és a -> operátorok balról jobbra hajtódnak végre, ezért a
struct tegla r, *rp = &r;
deklaráció esetén azr.pt1.x; rp->pt1.x; (r.pt1).x; (rp->pt1).x;kifejezések egymással egyenértékűek.
A . és -> struktúraoperátorok a függvény argumentumát tartalmazó ( ) kerek és az indexet tartalmazó [ ] szögletes zárójelekkel együtt a legmagasabb precedenciájú operátorok (l. a 2.1. táblázatot), így rendkívül szorosan kötnek. Például, ha adott a
struct { int hossz; char *str; } *p;deklaráció, akkor a
++p->hosszkifejezés a hossz változót inkrementálja és nem a p-t, mivel a precedenciaszabályoknak és a végrehajtási sorrendnek megfelelő alapértelmezés ++(p->hossz). A kötés zárójelezéssel változtatható meg, pl. a (++p)->hossz a hossz változóhoz való hozzáférés előtt inkrementálja a p értékét, a (p++)->hossz pedig a hozzáférés után inkrementál. Ez utóbbi esetben a zárójelek elhagyhatók.
Ugyanígy a *p->str előkészíti az str által kijelölt adatot, a *p->str++ inkrementálja str-t az általa címzett adat elővétele után és *p++->str pedig inkrementálja p-t, azután, hogy hozzáfért az str által címzett adathoz.
6.3. Struktúratömbök
Írjunk programot, amely megszámolja egy szövegben a C nyelv egyes kulcsszavainak előfordulását! A programban szükségünk lesz egy karaktersorozatokból álló tömbre az egyes kulcsszavak tárolásához, és egy egészekből álló tömbre a számlált értékek tárolásához. Ennek megvalósítására az egyik lehetőség, hogy két független, kulcsszo és kulcsszam nevű tömböt használunk:char *kulcsszo[NSZO]; int kulcsszam[NSZO];Az a tény, hogy a tömbök párhuzamosan léteznek, sugallja egy másik adatszervezési mód, a struktúratömbös megoldás bevezetését. Minden kulcsszóbejegyzés valójában egy adatpárból áll:
char *szo; int szam;és ezekből az adatpárokból létrehozhatunk egy tömböt. Az így deklarált struktúra:
struct kulcs { char *szo; int szam; } kulcstab[NSZO];Ez a deklaráció létrehoz egy kulcs típusú struktúrát és ezzel egy időben definiál egy kulcstab tömböt, ami ilyen típusú struktúrákból áll. A definíció egyben le is foglalja a tárterületet a tömb számára. Ennek a tömbnek minden eleme egy struktúra, ezért akár úgy is írhatnánk, hogy:
struct kulcs { char *szo; int szam; }; struct kulcs kulcstab[NSZO];Mivel a kulcstab struktúra a kulcsszavak állandó neveit tartalmazza, a legegyszerűbb, ha külső változóvá tesszük és definiáláskor egyszer és mindenkorra inicializáljuk. A struktúra inicializálása a korábban elmondottak szerint történhet, a definíciót a kezdeti értékek kapcsos zárójelek között elhelyezett listája követi:
struct kulcs { char *szo; int szam; } kulcstab[] = { "auto", 0, "break", 0, "case", 0, "char", 0, "const", 0, "continue", 0, "default", 0, /* ... */ "unsigned", 0, "void", 0, "volatile", 0, "while", 0, };A kezdeti értékeket a struktúratagoknak megfelelő adatpárok formájában soroltuk fel, de sokkal precízebb és szemléletesebb lenne, ha a tömb egyes soraihoz vagy elemi struktúráihoz tartozó kezdeti értékeket fognánk össze a kapcsos zárójelekkel, mint pl.
{ "auto", 0 },
{ "break", 0 },
{ "case", 0 },
...
esetben. Akkor, ha a kezdeti érték egyszerű adat vagy karaktersorozat, ill. az összes kezdeti érték fel van sorolva, akkor a belső kapcsos zárójelek elhagyhatók. Amennyiben a kulcstab utáni [] között nem szerepel a tömb mérete, akkor a fordítóprogram a kezdeti értékek leszámolásával határozza meg ezt az értéket (ahogyan erre korábban már utaltunk).
A kulcsszavakat számláló program a kulcstab definíciójával kezdődik. A main eljárás a bemeneti szöveget a getword függvény ismételt hívásával olvassa. A getword minden hívásakor egy szót olvas és a program minden beolvasott szót a 3. fejezetben leírt bináris keresést végző függvénnyel keres meg a kulcstab tömbben. A kereső függvény helyes működéséhez a kulcsszavaknak a tömbben növekvő (azaz ábécé-) sorrendben kell elhelyezkedni.
#include <stdio.h> #include <ctype.h> #include <string.h> #define MAXSZO 100 int getword(char *, int); int binsearch(char *, struct kulcs *, int); /* C kulcsszavait megszámoló program */ main() { int n; char szo[MAXSZO]; while (getword(szo, MAXSZO) != EOF) if(isalpha (szo [0])) if ((n = binsearch(szo, kulcstab, NSZO)) >= 0) kulcstab[n].szam++; for(n = 0; n < NSZO; n++) if(kulcstab[n].szam > 0) printf("%4d %s\n", kulcstab[n].szam, kulcstab[n].szo); return 0; } /* binsearch: a tab[0] ...tab[n-l] táblázatban szót keres */ int binsearch(char *szo, struct kulcs tab[], int n) { int felt; int also, felso, kozep; also = 0; felso = n - 1; while (also <= felso) { kozep = (also+felso)/2; if ((felt = strcmp(szo, tab[kozep].szo)) < 0) felso = kozep - 1; else if (felt > 0) also = kozep + 1; else return kozep; } return -1; }Hamarosan visszatérünk a getword függvényre is. Egyelőre csak annyit érdemes megjegyezni róla, hogy minden alkalommal, amikor beolvas a bemenetről egy szót, azt bemásolja az első argumentumaként megadott tömbbe.
Az NSZO a kulcstab táblázatban lévő kulcsszavak száma. Bár a kulcsszavakat minden további nélkül megszámolhatnánk, sokkal egyszerűbb és biztonságosabb, ha ezt a gépre bízzuk, főképp akkor, ha a lista változhat. Erre az egyik lehetőség, hogy a kezdeti értékek listáját egy null-mutatóval zárjuk és a kulcstab tömböt feldolgozó ciklust addig működtetjük, amíg csak meg nem találtuk a végét.
Ez azonban sokkal több annál, mint amire szükségünk van, mivel a tömb méretét már fordításkor meghatározza a fordítóprogram, és azután már nem változhat. A tömb mérete az egyes bejegyzések méretének és a bejegyzések számának szorzata, és a bejegyzések száma a
(kulcstab mérete) / (struct kulcs mérete)művelettel határozható meg. A fordítás idején hatásos sizeof unáris operátor bármilyen C nyelvű objektum méretének meghatározására használható. A
sizeof objektumés
sizeof (típusnév)kifejezések egy egész számot adnak eredményül, ami a megadott objektum vagy adattípus bájtokban mért mérete. (Szigorúan véve a sizeof operátor egy előjel nélküli egész számot ad, amelynek típusa az <stddef.h> headerben definiált size_t típus.) Az objektum változó, tömb vagy struktúra lehet. A típusnév lehet egy alapadattípus neve (pl. int vagy double) vagy egy származtatott típus (pl. struktúra vagy mutató).
A mi esetünkben a kulcsszavak száma a tömb méretének és egy elem méretének hányadosaként adható meg. Ennek kiszámításához, és így NSZO megadásához a #define utasítást használhatjuk a következő módon:
#define NSZO (sizeof kulcstab / sizeof(struct kulcs))Egy másik lehetőség, hogy a kifejezésbe a tömb méretének és egy meghatározott elem méretének hányadosát írjuk:
#define NSZO (sizeof kulcstab / sizeof kulcstab[0])Ez utóbbi alak előnye, hogy akkor sem kell módosítani, ha megváltoztatjuk a tömböt alkotó elemek típusát.
A sizeof operátor nem alkalmazható az #if feltételes fordítási parancsot tartalmazó sorokban, mivel a C előfeldolgozó rendszer nem elemzi a típusneveket, viszont a #define utasítás utáni kifejezésben már szerepelhet, mert ezt nem az előfeldolgozó, hanem a fordítóprogram értékeli ki.
Most még szólnunk kell a getword függvényről! A programunkhoz a pillanatnyilag szükségesnél sokkal általánosabb getword függvényt írtunk, de ettől az még nem lett bonyolultabb. A getword függvény a bemenetről előkészíti a következő „szót”, ahol a szót úgy értelmezzük, hogy az betűkből és számjegyekből álló, betűvel kezdődő karaktersorozat vagy egy tetszőleges, nem üres helyet jelentő karakter. A függvény visszatérési értéke a szó első karaktere, vagy az állomány végét jelző EOF, vagy maga a beolvasott karakter, ha az nem alfabetikus volt.
/* getword: beveszi a következő szót vagy karaktert a bemenetről */ int getword(char *szo, int lim) { int c, getch(void); void ungetch (int); char *w = szo; while (isspace(c = getch())) ; if (c != EOF) *w++ = c; if(!isalpha(c)) { *w = '\0'; return c; } for ( ; --lim > 0; w++) if (!isalnum(*w = getch())) { ungetch(*w); break; } *w = '\0'; return szo[0]; }A getword függvény használja a 4. fejezetben bemutatott getch és ungetch függvényeket. Amikorra egy alfanumerikus kulcsszó beolvasásra került, akkorra a getword már egy karakterrel többet olvasott be, amit az ungetch hívásával ad vissza a bemenetnek, hogy a getword következő hívásakor rendelkezésre álljon. A getword használja még az üres helyeket átlépő isspace, a betűket azonosító isalpha és a betűket, ill. számjegyeket azonosító isalnum függvényeket is, amelyek a <ctype.h> standard headerben találhatók.
6.1. gyakorlat. Az itt megírt getword függvény nem kezeli az aláhúzást, a karakteres állandót, a megjegyzést (commentet) és az előfeldolgozó rendszert vezérlő sorokat. Írjuk meg a függvény ezen hiányosságokat kiküszöbölő, javított változatát.
6.4. Struktúrákat kijelölő mutatók
A mutatók és a struktúratömbök együttes használatának bemutatására írjuk meg ismét a kulcsszavakat számláló programot úgy, hogy indexelt tömb helyett mutatókat alkalmazunk! A kulcstab külső deklarációját nem szükséges módosítani, de a main és a binsearch eljárásokat meg kell változtatni. Az új programok:#include <stdio.h> #include <ctype.h> #include <string.h> #define MAXSZO 100 int getword(char *, int); struct kulcs *binsearch(char *, struct kulcs *, int); /* C kulcsszavait megszámoló program - mutatós változat */ main () { char szo[MAXSZO]; struct kulcs *p; while (getword(szo, MAXSZO) != EOF) if (isalpha(szo[0])) if ((p=binsearch(szo, kulcstab, NSZO)) != NULL) p->szam++; for(p = kulcstab; p < kulcstab + NSZO; p++) if (p->szam > 0) printf("%4d %s\n", p->szam, p->szo); return 0; } /* binsearch: a tab[0] ... tab[n-l] táblázatban szót keres */ struct kulcs *binsearch(char *szo,struct kulcs *tab,int n) { int felt; struct kulcs *also = &tab[0]; struct kulcs *felso = &tab[n]; struct kulcs *kozep; while (also < felso) { kozep = also + (felso - also)/2; if ((felt = strcmp(szo, kozep->szo)) < 0) felso = kozep; else if (felt > 0) also = kozep + 1; else return kozep; } return NULL; }A programokban több dologra is szeretnénk felhívni a figyelmet! Elsőnek a binsearch függvény deklarációjára, ami azt jelzi, hogy a függvény egy egész adat helyett egy struct kulcs típusú struktúrát megcímző mutatóval tér vissza. Ezt a függvény prototípusában és a binsearch-ben egyaránt deklaráltuk. Ha a binsearch talál egy szót, akkor egy azt címző mutatóval tér vissza, ha a keresés sikertelen, akkor a visszatérési érték NULL.
Másodiknak érdemes megemlíteni, hogy a kulcstab elemeit mutatókkal jelöljük ki. Ez a binsearch jelentős megváltoztatását igényli. Az also és felso változókhoz rendelt kezdeti érték mutató lesz, ami a táblázat kezdetére, ill. éppen a vége utáni helyre mutat.
A középső elem helyének kiszámítása sem történhet a megszokott és egyszerű
kozep = (also + felso)/2; /* HIBÁS!!! */
összefüggéssel, mivel két mutató összeadása tilos. A kivonás művelete megengedett, így felso-also az elemek száma (ami int típusú) éskozep = also + (felso - also)/2;kifejezés a kozep értékét úgy állítja be, hogy az éppen az also és felso között középen elhelyezkedő elemre mutasson.
A legfontosabb módosítás, hogy az algoritmust úgy kellett átalakítani, hogy garantáltan ne adjon illegális vagy a tömbön kívüli elemet címző mutatót. A probléma az, hogy mind az &tab[-1], mind az &tab[n] kívül esik a tab tömb határain. Az első szigorúan tilos és a második alak is illegális hivatkozást eredményezhet. Mindazonáltal a C nyelv definíciója garantálja, hogy a címaritmetika egy tömb utolsó utáni elemével (itt tab[n]-nel) helyesen működjön.
A main eljárásban azt írtuk, hogy
for (p = kulcstab; p < kulcstab + NSZO; p++)
Ha p egy struktúra mutatója, akkor minden p-t használó aritmetikai műveletnél a cím-aritmetika figyelembe veszi a struktúra méretét, így p++ helyes mértékben inkrementálja a mutatót, hogy az a struktúrákból álló tömb következő elemére mutasson. Ennek következtében a ciklus ellenőrző feltétele a megfelelő időben állítja le a ciklust.
Ne gondoljuk azt, hogy a struktúra mérete az egyes tagok méreteinek összege! Mivel különböző objektumok összeigazításáról van szó, közöttük a struktúrában névvel nem rendelkező lyukak lehetnek! Így pl. ha a char típus egy bájtot, az int négy bájtot igényel, akkor a
struct { char c; int i; };struktúra nyolc bájton helyezkedik el, szemben a várt öt bájttal. A sizeof operátor mindig a tényleges méretet adja.
Végül még szólnánk a program formájáról: amikor egy függvény egy komplikált típusú adattal, pl. egy struktúra mutatójával tér vissza, mint a
struct kulcs *binsearch(char *szo, struct kulcs *tab, int n)esetben is, a függvény neve nehezen vehető észre vagy kereshető szövegszerkesztővel. Emiatt néha a
struct kulcs * binsearch(char *szo, struct kulcs *tab, int n)írásmódot szokták alkalmazni. Mindkét forma megfelelő, a választás közöttük ízlés kérdése.
6.5. Önhivatkozó struktúrák
Tételezzük fel, hogy az előbbinél sokkal általánosabb problémát akarunk megoldani: egy bemeneti szöveg összes szavának előfordulását akarjuk megszámolni. Mivel a szavak listája eredendően ismeretlen, így a hagyományos rendezés és bináris keresés nem használható. A lineáris keresést, amikor minden beolvasott szóról egy szólistán elölről kezdve végigmenve eldöntenénk, hogy már előfordult-e vagy sem, alkalmazhatnánk, de a program futási ideje rendkívül nagy lenne (pontosabban a futási idő valószínűleg a bemeneti szavak számának négyzetével arányosan növekedne). Hogyan kellene megszerveznünk az adatrendszerünket ahhoz, hogy hatékonyan megbirkózzunk a tetszőleges szavakból álló listával?
Az egyik lehetséges megoldás, hogy állandóan rendezett állapotban tartjuk a már feldolgozott szavak halmazát úgy, hogy a beérkezés sorrendjében a megfelelő helyre rakjuk a szavakat. Ezt azonban nem úgy csináljuk, hogy egy egyindexes tömbben folyton odébbtoljuk a már meglévő szavakat, hogy helyet szorítsunk egy új szónak. Ez a megoldás szintén nagyon nagy futási időt eredményezne, ezért helyette egy bináris fának nevezett adatstruktúrát alkalmazunk.
A bináris fa minden egyes különböző szóhoz egy „csomópontot” rendel, és minden csomópont a
- a szó szövegét megcímző mutatóból,
- a szó előfordulásának számából,
- a csomópont bal oldali gyermekét (leszármazottját) címző mutatóból,
- a csomópont jobb oldali gyermekét (leszármazottját) címző mutatóból
Az egyes csomópontokat úgy generáljuk, hogy bármelyik csomópont bal oldali részfája csupa olyan szót tartalmaz, amely lexikográfiásan kisebb nála, amíg a jobb oldali részfa a lexikográfiásan nagyobb szavakat tartalmazza. Így annak a mondatnak a bináris fája (a kis- és nagybetűk között nem téve különbséget és a vesszőt nem véve figyelembe), hogy „Jancsi bácsi rosszat álmodott, leértékelték a forintot és ebből tudta, hogy keserves világ következik” a következő módon néz ki:
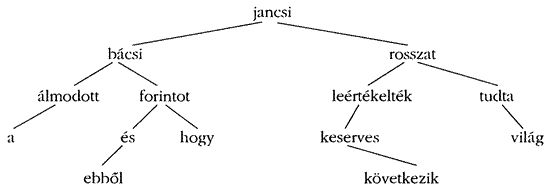
Azt, hogy az éppen beolvasott szó benne van-e a fában, úgy dönthetjük el, hogy elindulunk a gyökértől és a beolvasott szót mindig összehasonlítjuk az adott csomóponton tárolt szóval. Ha bárhol egyezést tapasztalunk, akkor a kérdést igenlő módon megoldottuk. Ha a szó kisebb a tárolt szónál, akkor a keresést a bal oldali gyermekkel, különben pedig a jobb oldalival folytatjuk. Ha a kívánt irányban nincs gyermek, akkor az éppen beolvasott szó nincs a fában és a hiányzó gyermek üres helyére kell beírnunk. Ez a folyamat rekurzívan ismételhető, mivel bármely csomópontból kiinduló keresés a csomópont gyermekéből kiinduló keresést használja. Ezért elég természetes, hogy a szavak beillesztésére, majd az eredmény kiírására rekurzív eljárásokat használunk.
Visszatérve az egyes csomópontok leírásához, látszik, hogy azok kényelmesen reprezentálhatók egy négy tagból álló struktúrával:
struct fcsomo { /* a fa csomópontja */ char *szo; /* a szó szövegének mutatója */ int szam; /* előfordulások száma */ struct fcsomo *bal; /* bal oldali gyermek */ struct fcsomo *jobb; /* jobb oldali gyermek */ };A csomópontoknak ez a rekurzív deklarációja elég megdöbbentően hat, de szintaktikailag korrekt. Az illegális, ha egy struktúra saját magára való hivatkozást tartalmaz, de a
struct fcsomo *bal;
a bal-t, mint az fcsomo-hoz tartozó mutatót deklarálja és nem egy fcsomo struktúrát.
Alkalmasint meg kell említeni az önhivatkozó struktúrák egy változatát, amikor két struktúra hivatkozik egymásra. Ez a következő módon oldható meg:
struct t { ... struct s *p /* p egy s típusú struktúrát */ }; /* címez */ struct s { ... struct t *q /* q egy t típusú struktúrát */ }; /* címez */A szavak előfordulását számláló program meglepően kicsi, mivel felhasználja a korábban már megírt getword függvényt. A main eljárás a getword függvénnyel szavakat olvas a bemenetről és az addtree függvénnyel elhelyezi azokat a fában.
#include <stdio.h> #include <ctype.h> #include <string.h> #define MAXSZO 100 struct fcsomo *addtree(struct fcsomo *, char *); void treeprint (struct fcsomo *); int getword(char *, int); /* szavak gyakoriságának számlálása */ main () { struct fcsomo *gyoker; char szo[MAXSZO]; gyoker = NULL; while (getword(szo, MAXSZO) != EOF) if (isalpha(szo[0])) gyoker = addtree(gyoker, szo); treeprint(gyoker); return 0; }Az addtree függvény rekurzív. A main egy szót helyez el a fa legfelső szintjén (a gyökéren). Ezután az addtree minden egyes lépésben az új szót összehasonlítja a csomópontban tárolt szóval és az eredménytől függően a bal vagy a jobb oldali ágon halad tovább az addtree rekurzív hívásával. A szó vagy megegyezik egy csomóponton tárolt szóval (ekkor az előfordulások számát tároló szam változót növelni kell eggyel), vagy elérjük a végjelzést (null-mutatót), ami azt jelzi, hogy egy új csomópontot kell létrehozni és a fához csatolni. Ha új csomópontot kellett létrehozni, akkor az addtree az azt címző mutatóval tér vissza, ami bekerül a szülő csomópontjába. Az addtree függvény:
struct fcsomo *talloc(void); char *strdup(char *); /* addtree: w elhelyezése a p című csomópontban vagy az alatt */ struct fcsomo *addtree(struct fcsomo *p, char *w) { int felt; if (p == NULL) { /* egy új szó érkezett */ p = talloc(); /* csinál egy új csomópontot */ p->szo = strdup(w); p->szam = 1; p->bal = p->jobb = NULL; } else if ((felt = strcmp(w, p->szo)) == 0) p->szam++; /* megismétlődött a szó */ else if (felt < 0) /* kisebb, a bal oldali részfába kerül */ p->bal = addtree(p->bal, w); else /* nagyobb, a jobb oldali részfába kerül */ p->jobb = addtree(p->jobb, w); return p; }Az új csomóponthoz szükséges tárolóhelyet a talloc függvény készíti elő és egy mutatóval tér vissza, ami az új csomópont elhelyezésére alkalmas szabad tárolóhelyet címzi. Az új szót az strdup függvény másolja az így kijelölt (de közelebbről nem ismert) helyre. (A talloc és strdup függvényeket később ismertetjük.) Az új csomópontban 1 kezdeti értéket kap az előfordulási darabszám és a két gyermeket kijelölő mutató értéke NULL lesz. Az addtree függvénynek ez a része csak a fán belüli keresés befejezésekor, azaz új csomópont beiktatásakor hajtódik végre. A talloc és a strdup hibaellenőrzését elhagytuk, ami persze nem túl szerencsés.
A treeprint függvény szétválogatott formában kinyomtatja a fát. Minden csomópontnál először kiírja a bal oldali részfát (minden, a csomópontbeli szónál kisebb szót), majd a csomópont szavát és ezután a jobb oldali részfát (minden, a csomópontbeli szónál nagyobb szót). Ha az olvasó bizonytalan a rekurzív eljárások használata terén, javasoljuk, hogy a fejezet elején megadott fa felhasználásával papíron, ceruzával szimulálja a treeprint működését.
/* treeprint : a p fa rendezett kiírása */ void treeprint(struct fcsomo *p) { if (p != NULL) { treeprint(p->bal); printf("%4d %s\n", p->szam, p->szo); treeprint(p->jobb); } }Meg szeretnénk jegyezni, hogy ha a fa kiegyensúlyozatlanná válik, mert a szavak nem véletlenszerűen érkeznek, akkor a program futási ideje nagyon megnőhet. A legrosszabb esetben, amikor a szavak már sorrendben vannak, a program az igen időigényes lineáris keresési algoritmust szimulálja. A bináris fáknak vannak olyan általánosításai, amikkel ez a kedvezőtlen viselkedés elkerülhető, de ezekkel itt nem foglalkozunk.
Mielőtt befejeznénk a példa elemzését, érdemes megvizsgálni a tárterület-lefoglalás egyik problémáját. Nyilvánvalóan jó lenne, ha a programban csak egyetlen tárterületlefoglaló eljárás lenne, amellyel különböző objektumok számára kérhetnénk helyet. Ha azonban ugyanaz az eljárás foglal helyet mondjuk egy char típusú adathoz tartozó mutató és egy struct fcsomo típusú struktúrához tartozó mutató számára, akkor két kérdés merül fel. Az első, hogy egy valós számítógép esetén hogyan elégítsük ki a különböző objektumokra vonatkozó elhelyezési követelményeket (pl., hogy egy egész típusú adatnak mindig páros tárcímen kell elhelyezkedni). A második kérdés, hogy milyen deklaráció teszi lehetővé, hogy a tárterület-lefoglaló eljárás különböző típusú mutatókkal térhessen vissza.
Az objektumok tárbeli elhelyezésére vonatkozó előírások viszonylag könnyen kielégíthetők, némi helyveszteség árán, ha megköveteljük, hogy a tárterület-lefoglaló eljárás mindig mutatóval térjen vissza, mivel az minden elhelyezési előírást kielégít. Az 5. fejezetben ismertetett alloc függvény semmiféle meghatározott elhelyezést nem garantál, ezért a programunkhoz a malloc standard könyvtári függvényt használtuk, ami kielégíti ezeket a követelményeket. A 8. fejezetben mutatunk egy lehetőséget a malloc megvalósítására.
Egy malloc-hoz hasonló függvény típusdeklarációja minden olyan nyelvben gondot okoz, amely a típusellenőrzést komolyan veszi. A C nyelvben a megfelelő módszert az jelenti, ha a malloc visszatérési értékét void típusú mutatóként deklaráljuk, majd explicit kényszerített típusmódosítással érjük el, hogy a mutató a kívánt típusú legyen. A malloc és a vele rokon függvények az <stdlib.h> standard headerben vannak deklarálva. A fentiek alapján írt talloc függvény a következő:
#include <stdlib.h> /* talloc: létrehoz egy fcsomo csomópontot */ struct fcsomo *talloc(void) { return (struct fcsomo *) malloc(sizeof(struct fcsomo)); }Az strdup függvény mindössze az argumentumában megadott karaktersorozatot másolja a malloc hívásával kapott helyre.
char *strdup(char *s) /* másolatot készít s-ről */ { char *p; p = (char *) malloc(strlen(s) + 1); /* a +1 hely a '\0' jelnek kell */ if (p != NULL) strcpy(p, s); return p; }A malloc függvény NULL értékkel tér vissza, ha nincs szabad hely és a strdup továbbadja ezt az értéket, amivel a hívó eljárásra bízza a hibakezelést.
A malloc függvény hívásával lefoglalt tárterület a free függvény hívásával szabadítható fel és tehető újra felhasználhatóvá. A kérdéssel részletesebben a 7. és 8. fejezetben foglalkozunk.
6.2. gyakorlat. Írjunk programot, ami beolvas egy C nyelvű programot és ábécésorrendben kiírja a változók azon csoportjait, amelyekben az első 6 karakter azonos, de a 7. karaktertől kezdődően valahol különböznek! A program ne vegye figyelembe a karaktersorozatokban és megjegyzésekben lévő szavakat! A feladatot úgy oldjuk meg, hogy a 6 parancssorból megadható paraméter legyen!
6.3. gyakorlat. Írjunk kereszthivatkozási programot, amely kiírja egy dokumentumban lévő szavakat az előfordulás, helyüket megadó sorszámokkal együtt! A program ne vegye figyelembe az olyan töltelékszavakat, mint „a”, „az”, „és” stb.!
6.4. gyakorlat. Írjunk programot, amely kiírja a beolvasott szöveg egyes szavait azok előfordulási gyakoriságának csökkenő sorrendjében! Minden szó elé írjuk ki az előfordulásának számát is!
6.6. Keresés táblázatban
Ebben a pontban egy táblázatkereső programcsomag gerincét írjuk meg, amivel bemutatjuk a struktúrák néhány további alkalmazási lehetőségét és tulajdonságát. A programcsomag elég tipikus, ilyen programok találhatók a makrófeldolgozók és fordítóprogramok szimbólumtáblázatot kezelő részében. Például nézzük a #define utasítást! Amikor valahol előfordul a
#define BE 1
programsor, akkor a BE nevet és az 1 helyettesítő szöveget egy táblázatban tárolja el a rendszer. Később, amikor a BE név előfordul egy olyan utasításban pl., mintallapot = BE;azt az 1 értékkel kell helyettesíteni.
A nevek és helyettesítő szövegek kezelésére két eljárást írtunk. Az install(s, t) függvény beírja az s nevet és a t helyettesítő szöveget a táblázatba (s és t mindkettő karaktersorozat). A lookup(s) függvény megkeresi s-t a táblázatban és egy mutatóval tér vissza, amely s táblázatbeli helyére mutat vagy NULL értékű, ha s nincs a táblázatban.
A kereséshez az ún. hash algoritmust használjuk, amely a bejövő nevet kis, nem negatív egész számmá alakítja és ezt a számot használja egy mutatókból álló tömb indexelésére. A tömb egy eleme a hash-kódolású neveket tartalmazó blokkok láncolt listájának kezdetére mutat. A tömbelem értéke NULL, ha a hash-kódnak megfelelő értékű név. A lista szerkezetét a következő oldalon található vázlat mutatja.
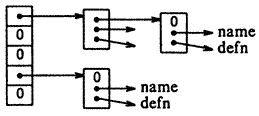
A lista minden blokkja egy struktúra, amely a név mutatóját, a helyettesítő szöveg mutatóját, valamint a lista következő blokkjának mutatóját tartalmazza. A következő blokk NULL mutatója jelzi a lista végét. A blokkot alkotó struktúra deklarációja:
struct nlist { /* a táblázat bejegyzései: */ struct nlist *kovetkezo; /* a következő elem a listában */ char *nev; /* a definiált név */ char *hszov; /* a helyettesítő szöveg */ };A megfelelő mutatótömb:
#define HASHMERET 101 static struct nlist *hashtab[HASHMERET]; /* a mutatók táblázata */A lookup és install függvényekben használt hash-kódot előállító függvény a karaktersorozatban lévő karaktereket összegzi az előző összeg megfelelően „összekavart” értékével és az eredmény ennek az összegnek a tömbmérettel való osztásakor kapott maradék. Ez nem a legjobb algoritmus, de mindenesetre rövid és egyszerű. A függvény programja:
/* hash: az s karaktersorozat hash-kódját generálja */ unsigned hash(char *s) { unsigned hashert; for (hashert = 0; *s != '\0'; s++) hashert = *s + 31 * hashert; return hashert % HASHMERET; }Az előjel nélküli típusmegadás (és az ehhez tartozó aritmetikai művelet) garantálják, hogy a hash-kód nem negatív.
A hash-kódolási eljárás létrehoz egy kezdő indexet a hashtab tömbhöz, és ha a karaktersorozat egyáltalán megtalálható valahol, akkor a blokkok itt kezdődő listájában kell lennie. A keresést a lookup függvény végzi. Ha a lookup megtalálja a táblázatban a bejegyzést, akkor annak mutatójával tér vissza, ha nem, akkor a visszatérési érték NULL.
#include <stdio.h> #include <string.h> /* lookup: s keresése a hashtab táblázatban */ struct nlist *lookup(char *s) { struct nlist *np; for (np = hashtab[hash(s)]; np != NULL; np = np->kovetkezo) if (strcmp(s, np->nev) == 0) return np; /* megtalálta */ return NULL; /* nem találta meg */ }A lookup függvényben lévő for ciklus a láncolt listában való haladás szokásos megvalósítása:
for (ptr = fej; ptr != NULL; ptr = ptr->kovetkezo) ...Az install függvény a lookup-ot használja annak eldöntésére, hogy a név benne van-e a táblázatban. Ha igen, akkor az új bejegyzés felülírja a régit, ha nem, akkor viszont egy új bejegyzés keletkezik. Az install visszatérési értéke NULL, ha bármilyen ok miatt nincs hely egy új bejegyzés létrehozására.
#include <stdlib.h> struct nlist *lookup(char *); char *strdup(char *); /* install: a nevet és a helyettesítő szöveget elhelyezi a hashtab-ban */ struct nlist *install(char *nev, char *hszov) { struct nlist *np; unsigned hashert; if ((np = lookup(nev)) == NULL) { /* nem találta */ np = (struct nlist *) malloc (sizeof(*np)); if (np == NULL || (np->nev = strdup(nev)) == NULL) return NULL; hashert = hash(nev); np->kovetkezo = hashtab[hashert]; hashtab[hashert] = np; } else /* már van ilyen bejegyzés */ free((void *)np->hszov); /* felszabadítja az előző helyettesítő szöveg helyét */ if((np->hszov = strdup(hszov)) == NULL) return NULL; return np; }
6.5. gyakorlat. Írjunk undef néven függvényt, amely a lookup és install függvények kezelte táblázatból töröl egy nevet és a hozzá tartozó definíciót!
6.6. gyakorlat. Ebben a részben ismertetett eljárások, valamint a getch és ungetch függvények felhasználásával valósítsa meg a #define utasítást feldolgozó egyszerű (argumentumokat nem használó) programot! A program legyen alkalmas a C nyelv szintaktikája szerinti, argumentum nélküli #define utasítások feldolgozására!
6.7. A typedef utasítás
A C nyelv typedef utasításával új adattípus-neveket hozhatunk létre. Például atypedef int Hossz;deklaráció bevezeti a Hossz típusnevet mint az int típusnév szinonimáját. A Hossz ezután szabadon használható deklarációkban, kényszerített típuskonverzióban stb., csakúgy, mint az int típusnév. Pl.:
Hossz len, maxlen; Hossz *hosszak[2];Hasonlóan a
typedef char *String;deklaráció hatására a String a char * karakteres mutató szinonimája lesz, így használható a következő deklarációkban, ill. kényszerített típuskonverzióban:
String p, sorptr[MAXSOR], alloc(int); int strcmp(String, String); p = (String) malloc(100);Vegyük észre, hogy a typedef-ben deklarált típus a változó nevének a helyén jelenik meg és nem közvetlenül a typedef utasításszó után! Szintaktikailag a typedef hasonló a tárolási osztályokat kijelölő extern, static stb. utsításokhoz. A typedef utasítással deklarált típus nevét nagy kezdőbetűvel írtuk, hogy kiemeljük a szövegkörnyezetből.
Most nézzünk egy bonyolultabb példát! A typedef utasítással rendeljünk új típusnevet a korábban használt fa csomópontjaihoz!
typedef struct fcsomo *Faptr; typedef struct fcsomo { /* a fa csomópontja: */ char *szo; /* a szöveg mutatója */ int szam; /* az előfordulások száma */ Faptr bal; /* bal oldali gyermek */ Faptr jobb; /* jobb oldali gyermek */ } Facsomo;Ez a deklaráció két új típusnevet, a Facsomo-t, ami egy struktúra és a Faptr-t, ami a struktúra mutatója, vezet be. Ezek felhasználásával a talloc függvény új programja:
Faptr talloc(void) { return (Faptr) malloc (sizeof(Facsomo)); }Ki kell hangsúlyoznunk, hogy a typedef utasítás semmilyen értelemben sem hoz létre új adattípust, mindössze a már meglévő adattípushoz rendel új típusnevet. Szemantikailag sem jelent újat: az így deklarált változók pontosan ugyanolyan tulajdonságúak, mint az explicit módon deklarált változók. Hatását tekintve a typedef hasonló a #define utasításhoz, azzal a különbséggel, hogy a typedef-et a fordítóprogram dolgozza fel, amely olyan bonyolult szöveges helyettesítésekkel is megbirkózik, amivel a #define utasítást feldolgozó előfeldolgozó rendszer nem képes. Például
typedef int (*MIF)(char *, char *);deklaráció létrehozza az MIF „Mutató Int értékkel visszatérő (két char * típusú argumentummal hívott) Függvényhez” nevű adattípust, ami olyan összefüggésekben használható, mint
MIF strcmp, numcmp;volt az 5. fejezet rendezőprogramjában.
Az esztétikai vonatkozásokon kívül a typedef utasítást két okból szokás alkalmazni. Az első, hogy a parametrizálás a program hordozhatóságánál okozhat gondokat. A typedef-fel deklarált adattípusok gépfüggetlenné tehetők a typedef módosításával. Az általános gyakorlat az, hogy a typedef-fel bevezetett neveket különböző egész típusú adatokhoz használjuk, és ekkor az éppen használt számítógép short, int és long adattípusaihoz megfelelő deklarációkat alakítunk ki. Erre jó példát mutatnak a a standard könyvtárban deklarált size_t és ptrdiff_t adattípusok.
A másik ok, amiért a typedef utasítást használjuk, hogy az így deklarált típusok javítják a program olvashatóságát, mert pl. a Faptr típusnevet könnyebb megérteni, mint egy bonyolult szerkezet mutatójának deklarációját.
6.8. Unionok
Az union egy olyan változó, amely különböző időpontokban különböző típusú és méretű objektumokat tartalmazhat úgy, hogy a fordítóprogram ügyel az objektumok méretére és tárbeli elhelyezésére vonatkozó előírások betartására. Az unionok alkalmazásával lehetővé válik, hogy azonos tárterületen különböző fajta adatokkal dolgozzunk, anélkül, hogy a programba géptől függő információkat kellene beépíteni. A C nyelv unionja analóg a Pascal record adattípusának egy változatával.
Az unionok használatának bemutatására szánt példánkat a fordítóprogram szimbólumtábla-kezelőjéből vettük. Tegyük fel, hogy az állandóink int, float vagy karakteres mutató típusúak lehetnek! Az adott állandó értékét a megfelelő típusú változóban kell tárolnunk, viszont a táblázat kezelése szempontjából, az a kényelmes, ha az értékek ugyanannyi tárterületet foglalnak el és ugyanazon a helyen tárolódnak, függetlenül a típusuktól. Ez az union használatának fő célja: egy olyan változó, amely megengedett módon többféle adattípus bármelyikét tárolhatja. Az union szintaxisa a struktúrákon alapszik:
union u_tag { int iert; float fert; char *sert; } u;Az így létrehozott u változó elegendően nagy lesz ahhoz, hogy az itt megadott három adattípus közül a legnagyobbat is tárolni tudja. Az u specifikált konkrét mérete a használt számítógéptől függ. A megadott három adattípus bármelyike hozzárendelhető u-hoz és ezután kifejezésekben használható mindaddig, amíg a felhasználás következetes: a művelet végén visszanyert típusnak meg kell egyeznie a legutoljára u-ba tárolt típussal. A programozó feladata, hogy nyomon kövesse, mikor és mit tárolt az unionba. Ha egy adatot adott típusként tárolunk el és más típusként nyerünk vissza, akkor az eredmény géptől függő lesz. Szintaktikailag az union tagjai az
union-név.tag-névvagy az
union-mutató->tag-névmódon érhetők el, csakúgy, mint a struktúrák tagjai. Ha az utype változót használjuk az u unionban éppen tárolt adattípus nyilvántartására, akkor az
if (utype == INT) printf("%d\n", u.iert); else if (utype == FLOAT) printf("%f\n", u.fert); else if (utype == STRING) printf("%s\n", u.sert); else printf("hibás tipus %d az utype-ban\n", utype);programrészlet lehetővé teszi az union tartalmának tárolt típustól függő kiíratását.
Az unionok előfordulhatnak struktúrákban és tömbökben is, és ez megfordítva is lehetséges. Egy struktúrán belüli unionhoz való hozzáférés (vagy az unionon belüli struktúrához való hozzáférés) módja megegyezik a beágyazott struktúrákhoz való hozzáférés módjával. Például az alábbi struktúratömböt definiálva a
struct { char *nev; int jelzok; int utype; union { int iert; float fert; char *sert; } u; } szimbtab[NSZIMB];az iert tagra a
szimbtab[i].u.iertformában hivatkozhatunk, és az sert karaktersorozat első karakteréhez az alábbi két forma bármelyikével hozzáférhetünk:
*szimbtab[i].u.sert szimbtab[i].u.sert[0]A valóságban az union olyan struktúra, amelyben a tagok közötti, báziscímhez viszonyított eltolás nulla. Ez a struktúra elegendően nagy ahhoz, hogy a legszélesebb tagot is tárolni tudja, miközben teljesül az unionban tárolt összes adattípusra a tárbeli elhelyezkedés minden előírása. Az unionokkal ugyanazok a műveletek végezhetők, mint a struktúrákkal: egy egységként kezelve részt vehetnek értékadásban és egyben másolhatók, előállíthatjuk a címüket és hozzáférhetünk a tagjaihoz.
Egy union csak az elsőként megadott tagjához tartozó típusú értékkel inicializálható, így az előbbi u unionhoz csak egész típusú kezdőérték rendelhető.
A 8. fejezetben található tárterület-lefoglaló program bemutatja, hogy egy union használatával hogyan lehet kikényszeríteni egy változó adott típusú tárterülethatárra való illeszkedését.
6.9. Bitmezők
Amikor a tárolóhely a szűk keresztmetszet, gyakran kényszerülünk arra, hogy több objektumot egyetlen gépi szóban helyezzünk el. Erre jó példa a fordítóprogram szimbólumtáblát kezelő része, ahol egybites jelzőket használunk. A kívülről kényszerített adatformátumok (pl. hardvereszközök illesztésekor) is gyakran igénylik egy gépi szó részéhez való hozzáférést.
Képzeljük el a fordítóprogramnak azt a részét, amelyik a szimbólumtáblát kezeli! Minden egyes programbeli azonosítóhoz bizonyos információk tartoznak: kulcsszó vagy sem, külső és/vagy statikus változó vagy sem stb. Ezek az információk legtömörebben egybites jelzőként tárolhatók egyetlen char vagy int típusú adatban.
Ezt szokásos módon úgy oldjuk meg, hogy definiálunk egy maszkhalmazt a megfelelő bitpozícióhoz, pl. az alábbiak szerint:
#define KULCSZSZO 01 #define EXTERNAL 02 #define STATIC 04vagy
enum { KULCSZSZO = 01, EXTERNAL = 02, STATIC =04 };
A számértékek bitpozíciót jelölnek ki, így kettő hatványának kell lenniük. Ezek után az egyes bitek a 2. fejezetben leírt bitműveletekkel (léptetés, maszkolás, komplementálás stb.) már hozzáférhetők.
Bizonyos programozási idiómák gyakran előfordulnak, mint pl. a
jelzok != EXTERNAL | STATIC;utasítás, amely 1-be állítja a jelzok változóban az EXTERNAL és STATIC állapotot jelző biteket, a
jelzok &= ~(EXTERNAL | STATIC);amely kikapcsolja (0-ba állítja) azokat, vagy az
if ((jelzok & (EXTERNAL | STATIC)) == 0) ...
amelynek értéke igaz, ha mindkét jelzőbit kikapcsolt állapotú.
Bár ezek az idiómák egyszerűen megjegyezhetők és használhatók, a C nyelv azt is lehetővé teszi, hogy egy gépi szón belül közvetlenül, minden bitenkénti logikai művelet nélkül, bitmezőket definiáljunk és használjunk. Egy bitmező (vagy röviden csak mező) egy számítógéptől függően definiált tárolási egységen (amit szónak fogunk nevezni) belül elhelyezkedő szomszédos bitek halmaza. A bitmező definíciójának és hozzáférésének a szintaxisa a struktúrák használatán alapszik. Például a szimbólumtáblához tartozó korábbi #define szerkezetek három bitmező definiálásával helyettesíthetők:
struct { unsigned int mkulcsszo : 1; unsigned int mextern : 1; unsigned int mstatic : 1; } jelzok;Ez a struktúra egy jelzok nevű változót definiál, amely három egybites mezőt tartalmaz. A mezőket unsigned int típusúnak deklaráltuk, hogy garantáltan előjel nélküli mennyiségek legyenek.
Az egyes bitmezőkre ugyanúgy hivatkozhatunk, mint a struktúrák tagjaira: jelzok, mkulcsszo, jelzok, mextern stb. A bitmezők a kis egész számokhoz hasonlóan viselkednek, és éppúgy, mint más egész számok, szerepelhetnek aritmetikai kifejezésekben, így az előbbi példák sokkal természetesebb módon úgy írhatók, hogy:
jelzok.mextern = jelzok.mstatic = 1;ami 1-be állítja a biteket,
jelzok.mextern = jelzok.mstatic = 0;ami 0-ba állítja a biteket vagy
if (jelzok.mextern == 0 && jelzok.mstatic == 0)
ami vizsgálja az állapotukat.
Majdnem minden, amit a bitmezőkkel kapcsolatban elmondtunk, az éppen használt számítógéptől függ. Az, hogy egy mező átlépheti-e a szóhatárt, szintén a géptől függ. A bitmezőknek nem kötelező nevet adni. A név nélküli (csak egy kettősponttal és a szélességgel megadott) bitmezők helykitöltésre használhatók. A speciális, 0 szélességű bitmezővel a következő szóhatárra való illeszkedést kényszerítjük ki.
Néhány számítógépnél a bitmezők kijelölése jobbról balra, más típusoknál balról jobbra történik. Ezért, bár a bitmezők igen hasznosak a belsőleg definiált adatstruktúrák tárolására, a külsőleg definiált (pl. egy hardvereszköztől érkező) adatok szétbontásakor nagyon meg kell gondolni a mezők elhelyezkedését. Sajnos emiatt a programok változhatnak és így nem lesznek hordozhatók. A bitmezők csak mint int adattípus deklarálhatók és signed vagy unsigned specifikátor írható elő rájuk. Ügyeljünk arra, hogy a bitmezők nem tömbök, nem címezhetők és így az & operátor sem alkalmazható rájuk!
| 5. FEJEZET | Tartalom | 7. FEJEZET |